Napkin
Napkin CLI application has a number of commands to develop, debug and execute specs
Usage: napkin [(-v|--verbose) | (-l|--log-level LOG_LEVEL)]
[--log-format LOG_FORMAT] [--log-file FILE]
Available options:
-v,--verbose Print debug log
-l,--log-level LOG_LEVEL Log severity level. Possible values: Debug, Info,
Notice, Warning, Error, Critical, Alert, Emergency.
(default: Notice)
--log-format LOG_FORMAT Log line format. Possible values: Simple, Server,
Json. (default: Simple)
--log-file FILE Path to log file
-h,--help Show this help text
Execute:
run Runs Napkin specs
auth Authenticates with Google BigQuery
list Lists available tables on database
aeda Performs AEDA over given relation
cleanup Remove temporary tables with namespaces/datasets
specified in a given spec file
tags List tags with their associated tables
Develop:
validate Validates YAML spec file
dump Performs a dry run and stores queries for inspection
repl Drops into Napkin repl
Documentation:
haddock Opens web page with Napkin haddocks
docs Opens web page with Napkin tutorial
IDE integration:
yaml-schema Stores YAML schema in a file
hie-bios Used by Haskell Language Server
Version:
version Prints Git SHA and version of the buildNapkin has number of global options, which are applicable to almost any command:
-
-l,--log-level- Allows to specify log level for the Napkin execution. -
-v,--verbose- Enables debug logging, equivalent of providing--log-level Debug. -
--log-format- Allows to choose desired format of the log messages. Currently supported: -
-h,--help- Displays traditional help message screen for each command. It is usually “safe” to append--helpto any Napkin command to know more about options it supports. Napkin will also display the--helpscreen when it meets the unfamiliar option.
Run
napkin run is used to execute Specs. It provides a handful of options that enable you to adjust how the spec is going to be executed. In a summary, you can:
- perform a partial run that will execute only a subset of defined tables,
- perform a dry-run and inspect the execution plan,
- pass spec arguments,
- enable CLI UI,
- override database connection settings.
Lets review the CLI command:
shell
napkin run --help
Usage: napkin run [-s|--spec-file SPEC_YAML]
[(-s|--spec-file SPEC_YAML) | (-y|--yaml-merge STRATEGY)
(-s|--spec-file SPEC_YAML)]
[--override /json/pointer={"json": "value"}]
[-C|--credentials-file FILE] [-u|--uri URI]
[--callback-http-port CALLBACK_HTTP_PORT]
[-S|--strict-mustache]
[--arg ARG=VALUE | --arg-json JSON | --arg-file FILE]
[-Q|--metadata-connection-string URI]
[--skip-all | --force-all | --only SELECTOR |
--force-only SELECTOR]
[--force SELECTOR | --force-with-downstream SELECTOR |
--force-with-upstream SELECTOR | --enable SELECTOR |
--enable-with-downstream SELECTOR |
--enable-with-upstream SELECTOR | --skip SELECTOR |
--skip-with-downstream SELECTOR |
--skip-with-upstream SELECTOR]
[(-p|--show-progress) | -w | --web PORT [--web-open-browser]
[--web-keep-running]] [--dev-slow | --dev-dead-slow]
[-r|--dry-run] [--condensed-logging] [--report REPORT_DIR]
[-j|--jobs NUM_TASKS] [--run-id RUN]
Runs Napkin specs
Available options:
-s,--spec-file SPEC_YAML Path to the spec yaml file
(default: "specs/spec.yaml")
-y,--yaml-merge STRATEGY YAML array merge strategy. Possible values:
MatchIndex, Prepend, Append, Replace.
--override /json/pointer={"json": "value"}
Set arbitrary JSON pointer (RFC 6901) in YAML spec
with the new value
-C,--credentials-file FILE
Path to database connection credentials file
-u,--uri URI Connection URI to create a database connection
postgres://user@remotehost/dbname (postgres:// # to use libpq defaults)
redshift://user@remotehost/dbname
bigquery://bigquery.googleapis.com/project
sqlite:///home/dev/myRepo/mySqlite.sqlite3 (sqlite::memory: # for in-memory database)
mssql:Server=remotehost;Database=dbname;uid=user
--callback-http-port CALLBACK_HTTP_PORT
Network port number for the napkin Auth server
-S,--strict-mustache Strict mustache validation mode
--arg ARG=VALUE Argument to be passed to spec
--arg-json JSON Spec arguments encoded as JSON object
--arg-file FILE Spec arguments stored in JSON file
-Q,--metadata-connection-string URI
An optional alternate connection string for tracking
napkin operations. Currently supports AWS S3 and file
based storage, e.g. files:/some/directory or
s3://bucket/prefix
--skip-all Table selector: Skip all tables, use other options to enable selected tables
--force-all Table selector: Force-enable update of all tables, use other options to skip selected tables
--only SELECTOR Table selector: Disable all tables except specified
--force-only SELECTOR Table selector: Disable all tables except specified which will be forced
--force SELECTOR Table selector: Force table update
--force-with-downstream SELECTOR
Table selector: Force table update, force downstream tables too
--force-with-upstream SELECTOR
Table selector: Force table update, force upstream tables too
--enable SELECTOR Table selector: Don't skip or force table, use the update strategy as specified in the Spec file
--enable-with-downstream SELECTOR
Table selector: Enable table update, enable downstream tables too
--enable-with-upstream SELECTOR
Table selector: Enable table update, enable upstream tables too
--skip SELECTOR Table selector: Skip table update
--skip-with-downstream SELECTOR
Table selector: Skip table update, skip downstream tables too
--skip-with-upstream SELECTOR
Table selector: Skip table update, skip upstream tables too
-p,--show-progress Show a progress bar if the terminal supports it
-w Start web UI server and open the browser
automatically. The server will keep running after
spec has finished.
--web PORT Start web UI server
--web-open-browser Open browser when server starts
--web-keep-running Do not quit server when spec is finished
--dev-slow Run slow (development flag)
--dev-dead-slow Run dead slow (development flag)
-r,--dry-run Simulate run and report which tables would've been
updated
--condensed-logging Reduce logging of non-action tasks such as skipped
tables.
--report REPORT_DIR Generate HTML report to a directory. Existing
directory contents will be erased. Use @TS to insert
timestamp and @RUN to insert run id.
-j,--jobs NUM_TASKS Restrict number of concurrent tasks.
--run-id RUN Allows to override run id, e.g. to match CI job id.
If not provided UUIDv4 is generated.
-h,--help Show this help text
Global options:
-v,--verbose Print debug log
-l,--log-level LOG_LEVEL Log severity level. Possible values: Debug, Info,
Notice, Warning, Error, Critical, Alert, Emergency.
(default: Notice)
--log-format LOG_FORMAT Log line format. Possible values: Simple, Server,
Json. (default: Simple)
--log-file FILE Path to log file
[0;1mTable selectors and SELECTOR types
Table selectors allow performing partial spec runs. This can be useful during
spec development. All options are applied in sequence to the execution plan.
--skip-all, --force-all, --only, and --force-only options can be specified as
a first table selector only. --only, --force-only, --skip, --enable, --force,
and --force-with-downstream options accept a SELECTOR, which can be one of:
* unprocessed table name, as it was defined in the spec,
e.g. [0;1m--skip spec:marketing_analytics,
* processed table name after all preprocessors have been applied,
e.g. [0;1m--skip db:development.john_marketing_analytics,
* task identifier, e.g. [0;1m--skip task:table/table2/create,
* table tag, e.g. [0;1m--enable tag:marketing.
Table names can be filtered using three matchers:
* literal table name, e.g. [0;1m--skip spec:marketing_analytics,
* table name pattern - an asterisk can be used as a wildcard at the
beginning or at the end of each table name segment,
e.g. [0;1m--force spec:prod_*.marketing_*,
* table name regex - regex has to be surrounded with /,
e.g. [0;1m--force spec:/^marketing.*/,
Specific parts of the table action can be targeted by adding a 'hooks:' or
'create:' suffixes, e.g. [0;1m--skip spec:create:marketing_analytics,
Please refer to the User Manual for further reference.
Example:
napkin run --only tag:marketing --enable spec:sales_totals --skip spec:marketing_mailing_*CLI UI
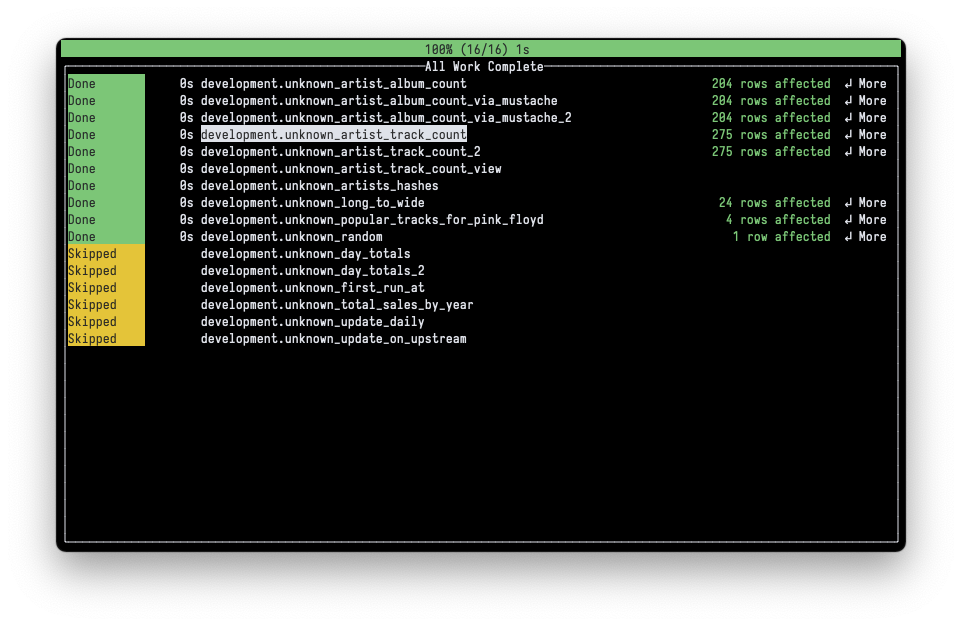
-
-p,--show-progress– will enable terminal UI that will display spec execution progress.
Dry runs
-
-r,--dry-run– will perform a dry run of the Spec. Napkin will always print Spec execution plan prior to executing queries, so this can be used to verify if partial run options have been applied correctly:
shell
napkin run --dry-run --force-only "spec:artist*" --skip "spec:*hashes*"
[2022-01-13 10:30:00][Info] Determining tables for update...
[2022-01-13 10:30:00][Info] Forced tables: none
[2022-01-13 10:30:00][Info] Skipped tables:
- artists_hashes -> development.unknown_artists_hashes
- day_totals -> development.unknown_day_totals
- day_totals_2 -> development.unknown_day_totals_2
- first_run_at -> development.unknown_first_run_at
- long_to_wide -> development.unknown_long_to_wide
- popular_tracks_for_pink_floyd -> development.unknown_popular_tracks_for_pink_floyd
- random -> development.unknown_random
- total_sales_by_year -> development.unknown_total_sales_by_year
- update_daily -> development.unknown_update_daily
- update_on_upstream -> development.unknown_update_on_upstream
[2022-01-13 10:30:00][Info] Unmanaged tables that will be used as an input in this run:
- chinook.Album
- chinook.Artist
- chinook.Track
[2022-01-13 10:30:00][Info] Managed tables that will be used as an input in this run, but will not be updated: none
[2022-01-13 10:30:00][Info] Managed tables that will be updated in this run:
- artist_album_count -> development.unknown_artist_album_count
- artist_album_count_via_mustache -> development.unknown_artist_album_count_via_mustache
- artist_album_count_via_mustache_2 -> development.unknown_artist_album_count_via_mustache_2
- artist_track_count -> development.unknown_artist_track_count
- artist_track_count_2 -> development.unknown_artist_track_count_2
- artist_track_count_view -> development.unknown_artist_track_count_view
[2022-01-13 10:30:00][Info] Estimated runtime: 35s
[2022-01-13 10:30:00][Warning] Dry run, aborting execution.
Partial spec runs
During Spec development it’s convenient to execute only tables the developer is working on. This allows for shorter feedback loop and can reduce costs as well. Napkin provides a number of command-line options that can be used to cherry-pick tables that will be executed during particular run. However, we don’t recommend using them for production runs.
All flags mentioned below will amend the execution plan in their order of appearance.
Initial execution plan:
-
--skip-allwill disable execution of all tables. Typically, it’d be combined with other options that will enable or force some tables. -
--force-allwill force execution of all tables. This overrides any update strategy that was set in table definitions. -
--onlywill disable execution of all tables and enable tables that fulfill the selector. This brings back any update strategy that was set in table definitions. Synonym of--skip-all --enable SELECTOR. -
--force-onlywill disable execution of all tables and force tables that fulfill the selector. This overrides any update strategy that was set in table definitions. Synonym of--skip-all --force SELECTOR.
Updating execution plan:
-
--forcewill force tables that fulfill the selector. This overrides any update strategy that was set in table definitions. -
--force-with-downstreamand--force-with-upstreamwill force tables that fulfill the selector as well as all tables depend on them on either direction. This overrides any update strategy that was set in table definitions. -
--enablewill void any changes to execution plan that were introduced with previous option for tables that fulfill the selector and will bring back any update strategy that was set in table definitions. -
--skipwill disable execution of the tables that fulfill the selector.
Table selectors
--only, --force-only, --force, --force-with-downstream, --enable, and --skip options accept a table selector. Napkin will fail when no tables match a selector, which may indicate user error.
-
db:PATTERN– will match against preprocessed table names (with all renaming applied). Wildcards or regular expressions may be used to match multiple tables. -
spec:PATTERN– will match against unprocessed table names, i.e. the table names as they were specified in the spec file. Wildcards or regular expressions may be used to match multiple tables. If no renaming was done with preprocessorsdb:andspec:selectors will have the same effect. -
tag:TAG– will match table tags. Wildcards or regular expressions cannot be used for tags.
Where PATTERN can be:
-
someproject.somedataset.sometable– an exact match. -
someproject.prod_*.*sales*– a wildcard can be used at the beginning and at the end of each name segment, segments are matched separately, so * will never expand beyond name segment:-
production.derived.*marketingwould matchproduction.derived.new_marketingbut notproduction.derived_update.marketingwhich a naive regex would otherwise match.
-
-
/REGEX/– a regular expression.
Example use cases
-
--force-only spec:top_artistswill disable all tables excepttop_artiststable which will be forced, -
--force-only spec:top_*will disable all tables and force all tables that have prefixtop_, -
--force-only db:*.*.top_*will disable all tables and force all tables that have prefixtop_in all projects and datasets, -
--skip-all --force-with-downstream tag:monthlywill disable all tables and force tables that have a tagmonthlyplus all tables that depend on them.
Meta arguments
-
--argARG=VALUEallows to provideARGspec argument with the string value ofVALUE. -
--arg-jsonwill accept JSON object as an argument that will be interpreted as key-value store. Values don’t need to be strings, they can be any valid JSON object. -
--arg-filewill read JSON object from a file.
Multiple options --arg* options can be used at the same time and all data provided will be collected.
Other options
-
-u,--uri– can be used to override database connection string. This can be useful, if development and production data sets are located on different DB servers. -
-C,--credentials-filecan be used to provide database credentials manually. Please refer to Connecting to the database page. -
--callback-http-port– can be used to override Napkin’s HTTP port used for handling BigQuery authorization.
Validate
napkin validate command allows to check the whole spec for:
- Napkin’s ability to correctly parse and process all the sql files.
- Napkin’s ability to compile and execute parts of the specs defined in Haskell.
- Validity of the built-in and user-defined preprocessors.
- Validity of the settings inside spec.yaml file.
- Correctness of mustache interpolation instructions.
- Absence of dependency loops across table definitions.
It is a good idea to check for the spec validness before committing the changes to the source code repository (git), so that other team members will not be surprised that napkin run is unable for do it’s job.
shell
napkin validate --help
Usage: napkin validate [-s|--spec-file SPEC_YAML]
[(-s|--spec-file SPEC_YAML) | (-y|--yaml-merge STRATEGY)
(-s|--spec-file SPEC_YAML)]
[--override /json/pointer={"json": "value"}]
[-i|--interactive] [-r|--rolling] [-S|--strict-mustache]
[--arg ARG=VALUE | --arg-json JSON | --arg-file FILE]
Validates YAML spec file
Available options:
-s,--spec-file SPEC_YAML Path to the spec yaml file
(default: "specs/spec.yaml")
-y,--yaml-merge STRATEGY YAML array merge strategy. Possible values:
MatchIndex, Prepend, Append, Replace.
--override /json/pointer={"json": "value"}
Set arbitrary JSON pointer (RFC 6901) in YAML spec
with the new value
-i,--interactive Watches for changed files and constantly revalidates
-r,--rolling Does not clear the screen in live validation mode
-S,--strict-mustache Strict mustache validation mode
--arg ARG=VALUE Argument to be passed to spec
--arg-json JSON Spec arguments encoded as JSON object
--arg-file FILE Spec arguments stored in JSON file
-h,--help Show this help text
Global options:
-v,--verbose Print debug log
-l,--log-level LOG_LEVEL Log severity level. Possible values: Debug, Info,
Notice, Warning, Error, Critical, Alert, Emergency.
(default: Notice)
--log-format LOG_FORMAT Log line format. Possible values: Simple, Server,
Json. (default: Simple)
--log-file FILE Path to log file- In
-i,--interactivemode, Napkin constantly monitors all the files and folders, mentioned in spec.yaml file automatically re-validates the spec on any change. It is convenient to havenapkin validate --interactiveprocess opened in a separate window, while you are working on the SQL files or the spec.yaml definition. - By default,
--interactivemode clears the screen before each validation cycle. To switch that feature off, you can use-r,--rollingmode, in which Napkin will constantly append validation status and error messages (in any) to the end of the output. - Napkin has number of strict mustache validation checks, which are not enabled by default. Use
-S,--strict-mustacheflag to enable additional checks (see mustache interpolation for details).
Without --interactive mode, napkin will print the single OK message to the terminal and exit with 0 exit code.
shell
napkin validate -s specs/spec.yaml
output
OK
With --interactive mode, Napkin constantly monitors for the changes in all files mentioned in the spec.yaml and re-validates as soon as it sees a change.

Dump
Besides knowing that your spec is “OK” (by using napkin validate command), Napkin also provides a way to see SQL queries, which Napkin would execute on a real database engine in by using napkin run command.
shell
napkin dump --help
Usage: napkin dump [-s|--spec-file SPEC_YAML]
[(-s|--spec-file SPEC_YAML) | (-y|--yaml-merge STRATEGY)
(-s|--spec-file SPEC_YAML)]
[--override /json/pointer={"json": "value"}]
[--arg ARG=VALUE | --arg-json JSON | --arg-file FILE]
[-o|--output-dir DIR]
[--skip-all | --force-all | --only SELECTOR |
--force-only SELECTOR]
[--force SELECTOR | --force-with-downstream SELECTOR |
--force-with-upstream SELECTOR | --enable SELECTOR |
--enable-with-downstream SELECTOR |
--enable-with-upstream SELECTOR | --skip SELECTOR |
--skip-with-downstream SELECTOR |
--skip-with-upstream SELECTOR]
[-e|--exclude-unmanaged-tables] [-S|--strict-mustache]
[--use-spec-names] [-i|--interactive] [-r|--rolling]
[--show-tasks-ids] [--show-tasks-graph]
Performs a dry run and stores queries for inspection
Available options:
-s,--spec-file SPEC_YAML Path to the spec yaml file
(default: "specs/spec.yaml")
-y,--yaml-merge STRATEGY YAML array merge strategy. Possible values:
MatchIndex, Prepend, Append, Replace.
--override /json/pointer={"json": "value"}
Set arbitrary JSON pointer (RFC 6901) in YAML spec
with the new value
--arg ARG=VALUE Argument to be passed to spec
--arg-json JSON Spec arguments encoded as JSON object
--arg-file FILE Spec arguments stored in JSON file
-o,--output-dir DIR Directory containing OUTPUT files (default: "dump")
--skip-all Table selector: Skip all tables, use other options to enable selected tables
--force-all Table selector: Force-enable update of all tables, use other options to skip selected tables
--only SELECTOR Table selector: Disable all tables except specified
--force-only SELECTOR Table selector: Disable all tables except specified which will be forced
--force SELECTOR Table selector: Force table update
--force-with-downstream SELECTOR
Table selector: Force table update, force downstream tables too
--force-with-upstream SELECTOR
Table selector: Force table update, force upstream tables too
--enable SELECTOR Table selector: Don't skip or force table, use the update strategy as specified in the Spec file
--enable-with-downstream SELECTOR
Table selector: Enable table update, enable downstream tables too
--enable-with-upstream SELECTOR
Table selector: Enable table update, enable upstream tables too
--skip SELECTOR Table selector: Skip table update
--skip-with-downstream SELECTOR
Table selector: Skip table update, skip downstream tables too
--skip-with-upstream SELECTOR
Table selector: Skip table update, skip upstream tables too
-e,--exclude-unmanaged-tables
Show only managed tables in the DOT graph exclusively
-S,--strict-mustache Strict mustache validation mode
--use-spec-names Use unprocessed table names as filenames
-i,--interactive Watches for changed files and constantly revalidates
-r,--rolling Does not clear the screen in live validation mode
--show-tasks-ids Show task Ids in tasks dot file
--show-tasks-graph Generate tasks dot graph
-h,--help Show this help text
Global options:
-v,--verbose Print debug log
-l,--log-level LOG_LEVEL Log severity level. Possible values: Debug, Info,
Notice, Warning, Error, Critical, Alert, Emergency.
(default: Notice)
--log-format LOG_FORMAT Log line format. Possible values: Simple, Server,
Json. (default: Simple)
--log-file FILE Path to log file-
-o,--output-dirparameter is used to specify output directory to put SQL files into. Directory will also contain dependency diagram (in form of.dotand.pdffiles) between the tables. -
-f,--forceflag is used to indicate, that it is OK for Napkin to override target directory. - By default, Napkin will add both managed and unmanaged tabled into a dependency diagram.
-e,--exclude-unmanaged-tablesflag forces Napkin to only include managed tables. - with
--use-spec-namesNapkin will use original table names (as declared in spec.yaml) for the file names in dump output. Otherwise, file names are equal to the table names after applying preprocessors. - In
-i,--interactivemode, Napkin constantly monitors all the files and folders, mentioned in spec.yaml file automatically re-dumps the spec on any change. It is convenient to havenapkin dump --interactiveprocess opened in a separate window, while you are working on the SQL files or the spec.yaml definition. - By default,
--interactivemode clears the screen before each dump cycle. To switch that feature off, you can use-r,--rollingmode, in which Napkin will constantly append dump status and error messages (in any) to the end of the output.
Usually napkin dump command will create following directory structure:
shell
napkin dump -o dump
output
dump
├── MANIFEST.txt
├─ artist_album_count
│ ├─ 1.sql
│ └─ program.log
├─ artist_album_count_via_mustache
│ ├─ 1.sql
│ └─ program.log
├─ day_totals_1
│ ├─ create
│ │ ├─ 3.sql
│ │ └─ program.log
│ └─ update
│ ├─ 3.sql
│ ├─ 4.sql
│ ├─ 5.sql
│ └─ program.log
├─ dependency_graph.dot
├─ dependency_graph.pdf
├─ dump.json
├─ long_to_wide
│ ├─ 1.sql
│ ├─ 2.sql
│ └─ program.log
└─ popular_tracks_for_pink_floyd
├─ 1.sql
└─ program.log
Some source sql folders, like day_totals_1 will produce multiple execution paths:
-
createfolder with a singlesqlfile – query, which Napkin would execute in order to createday_totals_1table is it is not exist yet. -
updatefolder with number ofsqlfiles in it – queries Napkin would execute in order to update already existingday_totals_1table.
Along with output SQL files, napkin dump command also generates dependency diagram between the tables in Graphviz format:
graph
digraph {
1 [label=Album
,shape=box
,style=dotted];
2 [label=Artist
,shape=box
,style=dotted];
3 [label=InvoiceLine
,shape=box
,style=dotted];
4 [label=Track
,shape=box
,style=dotted];
5 [label=artist_album_count
,fillcolor="#59a14f"
,fontcolor="#ffffff"
,style=filled];
6 [label=artist_album_count_via_mustache
,fillcolor="#edc948"
,fontcolor="#000000"
,style=filled];
7 [label=artist_album_count_via_mustache_2
,fillcolor="#b07aa1"
,fontcolor="#ffffff"
,style=filled];
8 [label=artist_hex
,fillcolor="#4e79a7"
,fontcolor="#ffffff"
,style=filled];
9 [label=artist_track_count
,fillcolor="#f28e2b"
,fontcolor="#000000"
,style=filled];
10 [label=artist_track_count_2
,fillcolor="#e15759"
,fontcolor="#ffffff"
,style=filled];
11 [label=artist_track_count_view
,fillcolor="#76b7b2"
,fontcolor="#000000"
,style=filled];
12 [label=popular_tracks_for_pink_floyd
,fillcolor="#59a14f"
,fontcolor="#ffffff"
,style=filled];
1 -> 5;
1 -> 6;
1 -> 7;
1 -> 9;
1 -> 11;
1 -> 12;
2 -> 5;
2 -> 6;
2 -> 7;
2 -> 8;
2 -> 9;
2 -> 11;
2 -> 12;
3 -> 12;
4 -> 9;
4 -> 11;
4 -> 12;
9 -> 10;
}
In PDF format, this diagram (download) looks like that:

Haddock
shell
napkin haddock --help
Usage: napkin haddock
Opens web page with Napkin haddocks
Available options:
-h,--help Show this help text
Global options:
-v,--verbose Print debug log
-l,--log-level LOG_LEVEL Log severity level. Possible values: Debug, Info,
Notice, Warning, Error, Critical, Alert, Emergency.
(default: Notice)
--log-format LOG_FORMAT Log line format. Possible values: Simple, Server,
Json. (default: Simple)
--log-file FILE Path to log fileNapkin is written in Haskell and currently exposes all internal APIs for external use (as it allows meta-programming, expressing SQL statements programmatically, etc.).
Links to the Napkin Haskell API documentation for each individual version can be found here.
You can always “ask” Napkin CLI for the exact link to the API reference for the currently installed version. It will open a browser with an API docs for the exact git commit SHA Napkin was built from.
shell
napkin haddock
output
Opening "https://napkin-public-storage-bucket.s3.us-east-1.amazonaws.com/haddock/git-hash/a8811868647ccc54e5c716e1a2781fe1c8b2ef9b/index.html" URL in the browser
Docs
shell
napkin docs --help
Usage: napkin docs
Opens web page with Napkin tutorial
Available options:
-h,--help Show this help text
Global options:
-v,--verbose Print debug log
-l,--log-level LOG_LEVEL Log severity level. Possible values: Debug, Info,
Notice, Warning, Error, Critical, Alert, Emergency.
(default: Notice)
--log-format LOG_FORMAT Log line format. Possible values: Simple, Server,
Json. (default: Simple)
--log-file FILE Path to log fileAs well as for Haddock API reference, Napkin CLI can be asked for a link to this documentation site.
shell
napkin docs
Opening "https://docs.napkin.run/fundamentals" URL in the browser
REPL
napkin repl can be useful when using advanced meta-programming features. When this command is used Napkin will spawn Haskell GHCI session. Spec file has to be provided, so the REPL session will be configured appropriately.
shell
napkin run --help
Usage: napkin repl [-s|--spec-file SPEC_YAML]
[(-s|--spec-file SPEC_YAML) | (-y|--yaml-merge STRATEGY)
(-s|--spec-file SPEC_YAML)]
[--override /json/pointer={"json": "value"}]
[--arg ARG=VALUE | --arg-json JSON | --arg-file FILE]
Drops into Napkin repl
Available options:
-s,--spec-file SPEC_YAML Path to the spec yaml file
(default: "specs/spec.yaml")
-y,--yaml-merge STRATEGY YAML array merge strategy. Possible values:
MatchIndex, Prepend, Append, Replace.
--override /json/pointer={"json": "value"}
Set arbitrary JSON pointer (RFC 6901) in YAML spec
with the new value
--arg ARG=VALUE Argument to be passed to spec
--arg-json JSON Spec arguments encoded as JSON object
--arg-file FILE Spec arguments stored in JSON file
-h,--help Show this help text
Global options:
-v,--verbose Print debug log
-l,--log-level LOG_LEVEL Log severity level. Possible values: Debug, Info,
Notice, Warning, Error, Critical, Alert, Emergency.
(default: Notice)
--log-format LOG_FORMAT Log line format. Possible values: Simple, Server,
Json. (default: Simple)
--log-file FILE Path to log fileYaml-Schema
shell
napkin yaml-schema --help
Usage: napkin yaml-schema OUTPUT
Stores YAML schema in a file
Available options:
OUTPUT Name of the file to put generated yaml schema
-h,--help Show this help text
Global options:
-v,--verbose Print debug log
-l,--log-level LOG_LEVEL Log severity level. Possible values: Debug, Info,
Notice, Warning, Error, Critical, Alert, Emergency.
(default: Notice)
--log-format LOG_FORMAT Log line format. Possible values: Simple, Server,
Json. (default: Simple)
--log-file FILE Path to log fileMany modern text editors and IDEs have (either native or through plugins) support for YAML Schema to enhance the process of editing complex YAML files. Napkin provides a way to export YAML schema to an external file - so it is possible to configure your editor properly.
In addition, if your editor or plugin supports that feature, you can point it to the web link with a latest YAML schema. YAML schemas for previous releases can be found here.
-
OUTPUTparameter is a path to a file to put generate yaml schema for the spec.yaml config.
For example:
shell
napkin yaml-schema $HOME/napkin.schema
Saving YAML schema to a file: /Users/user/napkin.schema
Hie-Bios
shell
napkin hie-bios --help
Usage: napkin hie-bios [-s|--spec-file SPEC_YAML]
[(-s|--spec-file SPEC_YAML) | (-y|--yaml-merge STRATEGY)
(-s|--spec-file SPEC_YAML)]
[--override /json/pointer={"json": "value"}]
[GHC_OPTIONS]
Used by Haskell Language Server
Available options:
-s,--spec-file SPEC_YAML Path to the spec yaml file
(default: "specs/spec.yaml")
-y,--yaml-merge STRATEGY YAML array merge strategy. Possible values:
MatchIndex, Prepend, Append, Replace.
--override /json/pointer={"json": "value"}
Set arbitrary JSON pointer (RFC 6901) in YAML spec
with the new value
GHC_OPTIONS List of extra GHC arguments to pass
-h,--help Show this help text
Global options:
-v,--verbose Print debug log
-l,--log-level LOG_LEVEL Log severity level. Possible values: Debug, Info,
Notice, Warning, Error, Critical, Alert, Emergency.
(default: Notice)
--log-format LOG_FORMAT Log line format. Possible values: Simple, Server,
Json. (default: Simple)
--log-file FILE Path to log filenapkin hie-bios provides support for advanced meta-programming with Napkin. This command is not supposed to be used directly by the user.
Haskell Language Server sets HIE_BIOS_OUTPUT environment variable, which is used by Napkin as a file name to write all inferred and user-supplied options to. For debug purposes, Napkin defaults file location to hie-bios.txt in the current working directory.
shell
HIE_BIOS_OUTPUT=/dev/tty napkin hie-bios -s specs/spec.yaml
...
-package
containers
-package
napkin
-package
ordered-containers
-package
unordered-containers
-package
text
-package
containers
-package
aeson
...
-XBangPatterns
-XBinaryLiterals
-XConstrainedClassMethods
-XConstraintKinds
-XDeriveDataTypeable
-XDeriveFoldable
...
Usually, it is enough to add the hie.yaml to the root of the Napkin project for the HLS plugin from your editor to load.
hie.yaml
cradle:
bios:
shell: napkin hie-bios --spec-file specs/spec.yaml
-
GHC_OPTIONS- List of additional GHC options, which Napkin will pass to the GHC through HLS.
Version
shell
napkin version --help
Usage: napkin version
Prints Git SHA and version of the build
Available options:
-h,--help Show this help text
Global options:
-v,--verbose Print debug log
-l,--log-level LOG_LEVEL Log severity level. Possible values: Debug, Info,
Notice, Warning, Error, Critical, Alert, Emergency.
(default: Notice)
--log-format LOG_FORMAT Log line format. Possible values: Simple, Server,
Json. (default: Simple)
--log-file FILE Path to log fileNapkin can print current version, release data and exact git commit on it was built.
For example:
shell
napkin version
Napkin version: 0.5.11
Git commit hash: a8811868647ccc54e5c716e1a2781fe1c8b2ef9b
Built at: 2022-01-04 10:24:21.398355 UTC
If you want to install a newer version of Napkin – please, follow installation instructions.